音響信号からの説明文の生成
どんな研究?
話し言葉以外の様々な音に対して、その音がどんな音なのかを説明するテキストを生成する研究です。
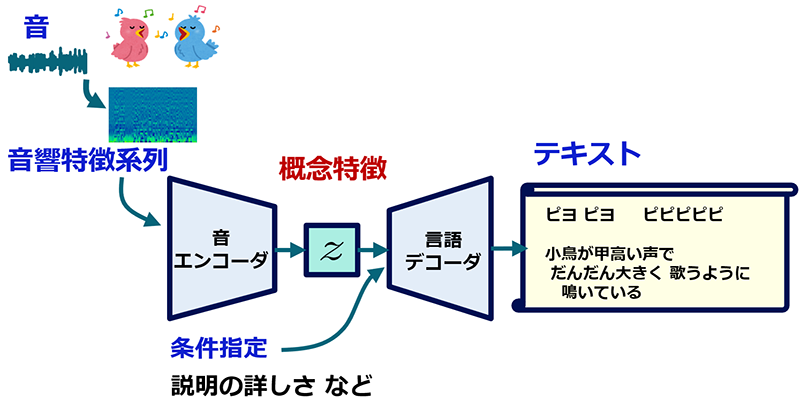
基本的な仕組みは、エンコーダ・デコーダ型のニューラルネットワークです。音の信号を「音エンコーダ」により低次元の特徴に変換し、これを元に言語生成器(言語デコーダ)により文章を生成します。
説明文生成の基本的な仕組み
どこがすごい?
私たちは、音響信号からの説明文生成の課題に最も早くから取り組んでいる研究チームの一つです。
国際会議 DCASE 2019 において Best Paper Award を受賞 [1]、また、同会議の国際コンペティション「DCASE2020チャレンジ」の「説明文生成部門」にて世界一位を獲得しました。[2, 3]
さらに、生成した文章を効果的に動画中に表示する方法についても研究しています。[4]。
この技術は、心音からの説明文生成にも適用できます。[5]
生体音の取得はスマホや簡易なデバイスを用いて日常生活の中でも行えると考えられますが、取得した音の意味の理解は、現在のところ経験を積んだ医療者によらなければなりません。このが進展すれば、このギャップが埋まり、必要な場合に早期に医療機関の受診を自動的に勧奨することなども可能になると考えられます。
めざす未来
- 様々な音を目で見ることができるユーザインタフェース
- スマホや携帯型の装置でとらえた生体音(心音、呼吸音、腸の音など)に対して、正常かどうかや、異常な場合の緊急度などを判断して分かりやすく説明文で提示する “AI聴診器”
関連文献
- Shota Ikawa, Kunio Kashino, Neural audio captioning based on conditional sequence-to-sequence model, Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE) (2019).
- https://group.ntt/jp/topics/2020/07/22/dcase2020/
- Daiki Takeuchi, Yuma Koizumi, Yasunori Ohishi, Noboru Harada, Kunio Kashino, Effects of Word-Frequency Based Pre- and Post- Processings for Audio Captioning, Proc. of DCASE Workshop (2020).
- Fangzhou Wang, Hidehisa Nagano, Kunio Kashino, Takeo Igarashi, Visualizing Video Sounds With Sound Word Animation to Enrich User Experience. IEEE Transactions on Multimedia (2016).
- 柏野邦夫, 中野允裕, 渋江遼平, 塚田信吾, 友池仁暢,心音に対する説明文の自動生成, 第 19 回情報科学技術フォーラム (2020).
連絡先
柏野 邦夫 (Kunio Kashino)
コミュニケーション科学基礎研究所 メディア情報研究部 生体情報処理研究グループ