Theoretical Understanding of Source-free Domain Adaptation
[Japanese|English]
Abstract
Deploying AI models in a new environment requires significant costs related to the collection of labeled data fro model retraining. Source-free Domain Adaptation (SFDA) addresse this issue by adapting the model to a new environment using only unlabeled data from the target environment.This work show a unified theoretical understanding of the existing SFDA methods, which has been unexplored, and we build an improved SFDA method based on the obtained theoretical insights.
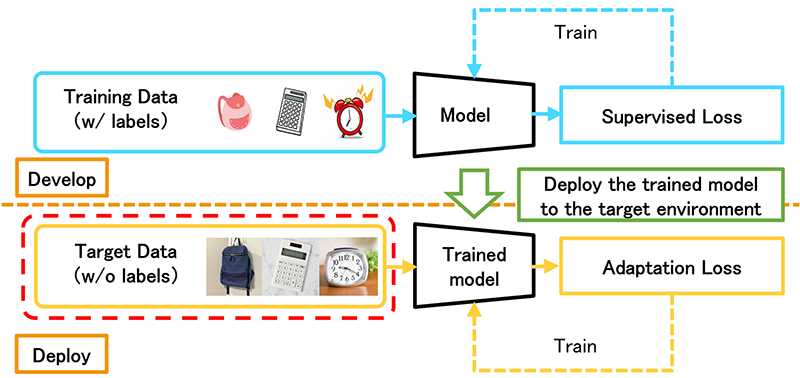
Contributions
Based on the theory of self-training, which is investigated in a different research area, we present a unified theoretical understanding for the existing SFDA methods that have been developed individually. This finding shows that it is important to perform both consistency training and diversity training in SFDA. We also find two theoretical insights that is useful for improving SFDA methods.
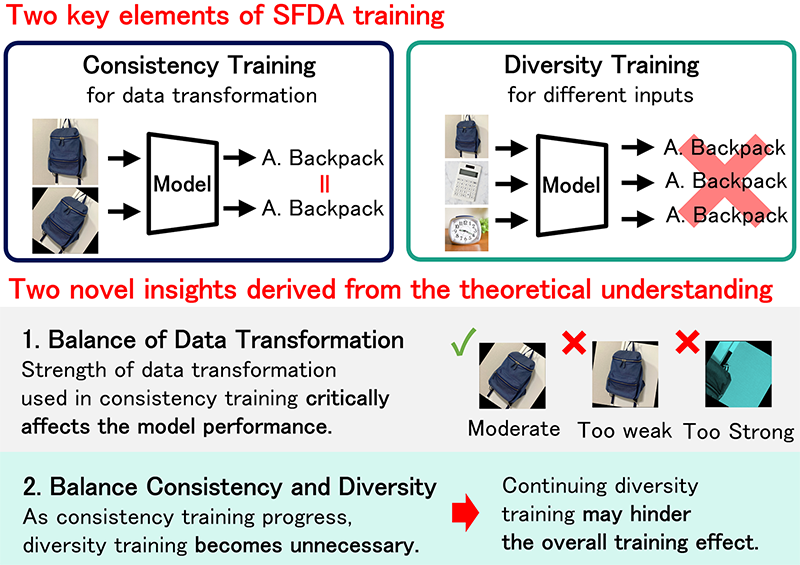
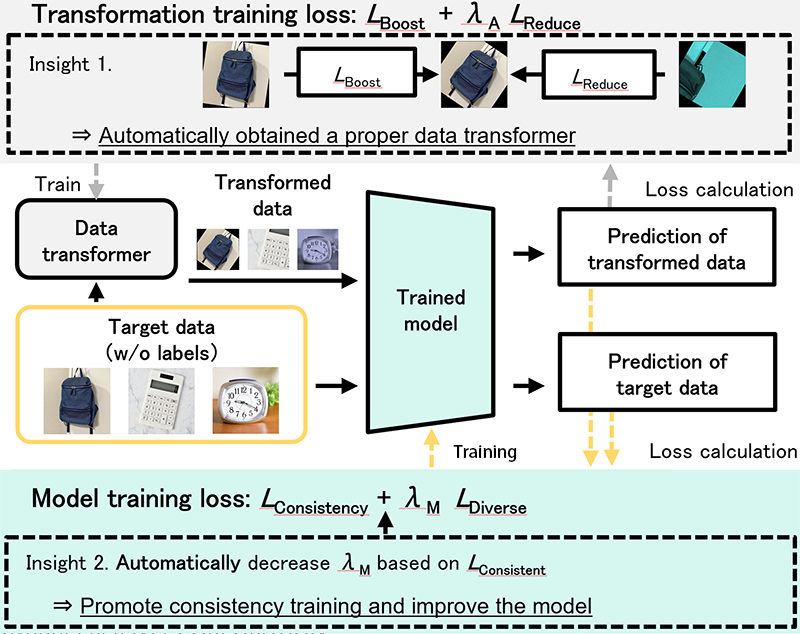
Proposed Method
This work propose a method to improve the existing source-free domain adaptation based on the obtained insights. The insights are realized as a method to adjust the data transformation and a method to adjust the loss balance between consistency and diversity.
Future work
SFDA is attracting significant attention due to its practical utility in that it enables flexible adaptation of the model to new environments while preserving the privacy and copyright of the source training data. Our theoretical understanding of SFDA will improve the reliability of SFDA techniques and serve as a foundation for the creation of new SFDA methods.
Publications
- Y. Mitsuzumi, A. Kimura, H. Kashima, “Understanding and Improving Source-free Domain Adaptation from a Theoretical Perspective,” in Proc. the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 28515-28524, 2024.
Contact
Yu Mitsuzumi
Recognition Research Group, Media Information Laboratory, NTT Communication Science Laboratories
Related Research
- Theoretical Understanding of Source-free Domain Adaptation
- Deep Image Generation Based on Optics and Physics
- Controlling the Color Appearance of Objects by Optimizing the Illumination Spectrum
- The Trichromatic Lottery Ticket Hypothesis
- Efficient Algorithm for K-Multiple-Means
- Unsupervised Learning of 3D Representations from 2D images
- Generalized Domain Adaptation
- Efficient Algorithm for Anchor Graph Hashing
- Zero-shot knowledge distillation
- Human pose estimation with acoustic signals