
NICの研究開発
AI活用によるネットワークキャリアのオペレーション高度化
~自己進化型ZTOフレームワーク: 異常検知AI(平常時乖離分析) 第1回~
NIC ネットワークオペレーションプロジェクト
渡部 修平(わたなべ しゅうへい)
#自己進化型ZTO#NW-AI#異常検知
2025/5/8
はじめに
現在研究所にて取り組んでいる、AIを活用したプロダクト実用化開発として「自己進化型ZTOフレームワーク」(※)の取り組みを紹介しましたが、ここから2回に分けて、自己進化型ZTOフレームワークへ組み込まれたNW-AI機能のひとつである異常検知NW-AIについて紹介します。
まず、第1回目となる本記事では、異常検知NW-AIの紹介に入る前の導入編としてネットワークオペレーションの現場で行われる異常検知がどういったものなのか、どのような手段で実現されているのかを説明します。
続いて、第2回目の次回記事では、異常検知NW-AIの根幹である平常時乖離分析機能(メトリクス・ログ分析技術)について説明します。
第1回 ネットワークにおける異常分析と方法について(本記事)
第2回 平常時乖離分析機能(メトリクス,ログ分析技術)について
前記事のリンク:
AI活用によるネットワークキャリアのオペレーション高度化 ~自己進化型ZTOフレームワーク~
(※)
ネットワークの異常と検知
ネットワークの異常
昨今のネットワークはインターネットに代表されるようにみなさんの生活の中で様々な場所で活用されていますが、その実体は使用目的に応じてサーバやネットワーク接続機器などの多種多様な装置を組み合わせて構成されています。 日々使っているパソコンが突然壊れて動かなくなってしまうように、ネットワークを構成する装置も使っているエラーを起こして壊れたり、動きが悪くなってしまうことがあります。その結果、通信が切断したり遅延が発生してしまったりとネットワークを利用するサービスにも影響を及ぼしてしまいます。この装置故障による通信断のように、「ネットワークの異常」とは通常では起こらないことや、正常な動作と比べて明らかに違う動きのことを指します。
ネットワークの利用は旧来のWebブラウジングやメールから現在主流となっている動画ストリーミング、クラウドサービスなど高度なサービスの形に変化しつづけており、生活の中での利用拡大に合わせて、社会的な重要性も年々高まっている状況です。 そして一度ネットがつながらない、途切れる、遅いなどの問題が発生してしまうと、企業の活動や家庭生活など社会活動そのものが止まってしまうなどの大きな影響がでてしまいます。そのため、ネットワークオペレーションの現場では利用者がネットワークを快適に利用できるよう、構成する装置が正常動作している状態を維持する必要があります。
異常の検知
ネットワークの正常な状態を出来る限り維持していくためには、ケガや病気への対処と同じように不調を早期に発見し、迅速に対処するという所が重要になります。そのため、ネットワークオペレーションの中では異常を認識するための仕組み(異常検知)を準備し、迅速な異常の対処に備えることが一般的であり、その手段中でも代表的なメトリクス分析とログ分析の2つについて紹介します。
メトリクス分析
メトリクスとは?
各種装置が正常に動作しているかどうかを判断するために用いられる指標が「メトリクス」です。装置の健康状態や性能などを数字や文字で表したもので、人間で例えるなら体温や心拍数などが該当します。ネットワークオペレーションの現場ではトラフィック量、CPU使用率、遅延、パケットロスなど、多種多様な値がメトリクスとして活用されています。
メトリクスを用いた異常判別の例
メトリクスの異常判別ですが、一般的には予め正常となる値の範囲を決めておき、その範囲から外れた際に異常として判別を行います。
ここで、先に述べた「ネットワーク異常」の例として装置故障による通信断が発生した状況を想定し、その際のグラフの例を以下(図1)で示します。
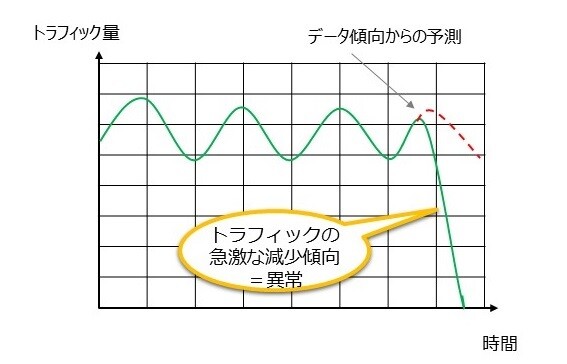
図1の緑の線はメトリクスのサンプルとしてトラフィック量の時間変化をグラフで可視化したものを示しています。 サンプルではある時刻でトラフィックが急減し、それまでのデータ傾向から予測されたデータである赤の破線で示した値からの外れ=異常と判別している例を表しています。 実際のネットワークの中では例で示した装置故障に起因するトラフィックの変動のように、状況に応じてその流量が変化することが多々あります。 変化状況によってはネットワーク全体のパフォーマンスに影響がでてしまうため、オペレーションの現場では素早い対応が求められます。 そのため、異常に素早く気づき対処に取り掛かるための仕組みとしてメトリクスを用いた異常判別が活用されています。
ログ分析
装置のログとは?
ログを簡単に表現すると、装置が何をしたのか、どんな問題があったのかを記録する「日記」のようなものです。装置内で動作する様々なプログラムがエラー、動作状況、設定変更などの記録を何かあった際に原因を探る手掛かりになるように書き出します。
ログを用いた異常判別の例
ログの分析についてもメトリクスの分析同様に「ネットワークの異常」として通信断が発生した状況を想定し、その際に発生した簡単なログのサンプルを以下(図2)に示します。

このログを用いてどのように異常を判別していくかですが、まず1と4行目は設定に従って装置のfirewallを通過したことを示したログであり、発生した通信断という事象とは関連性が低い正常な通信の記録であると想定できます。一方で、2行目に記録されたログはBGPの切断ログ、3行目はBGPが接続されたログであり、その内容からBGPがホールドタイムアウトで一度切断し、再接続されたことが確認でき、router1の対向装置との間で一時的に異常が発生したという分析(図3)を行うことができます。

ここまでサンプルログを用いて異常ログの判別について解説しましたが、一般的にログは利用するOSやソフトウェアに応じて様々な形式や粒度で情報が記録されていきます。そのため、読み取るための知識やノウハウを使いながら、普段は記録されないとか頻度や順序が違うなどのログの記録状況の変化から異常な状態であることを読み取っていく必要があります。そうして読み取ったログのメッセージには詳細な情報が残っているため異常を判別すると共にその原因究明をして対処を行う所にログ分析は活用されています。
まとめ
ここまでで簡単な例を用いてメトリクスとログを使ったネットワークにおける異常検知について見てきましたが、実際のキャリアネットワークにおいては一日で数百万行に及ぶログが生成され、時々刻々と変化する数百万のメトリクスを監視します。この膨大な量のメトリクスとログの変化から異常な状態を人の目でリアルタイムに判断していくことは非常に困難であり、さらには一つでも重大な異常の見落としをしてしまうと対処の初動が遅れてしまうことに繋がり、結果的に利用者に多大な影響が出てしまう事になります。
そのため、私たちのチームではAIを活用して膨大なメトリクスやログから平常時の状態を学習しておき、そこから外れた異常な状態をもれなく即座に検知するNW-AIである平常時乖離分析機能を開発しております。次回の第2回記事ではこの平常時乖離分析機能についてもう少し詳しくご紹介したいと思います。
関連するプロジェクト
プロジェクト一覧へ
採用情報
採用情報