仮想データレイク・ブローカ
組織・企業の垣根と距離の壁を超えた多種・大量データの相互利活用を実現する技術

技術背景・課題
経済的発展と社会課題解決の両立が期待されるデータ駆動型社会の実現には、組織・企業の垣根と距離の壁を越えた多種・大量データの相互利活用を促進していく必要があります。
具体的には、購買履歴や製造実績など蓄積されたデータ(ファイルやオブジェクト)の利活用ニーズに加え、センサ値や制御信号など時々刻々と変化するデータ(ストリームデータ)の利活用ニーズがあります。また、業界単位でデータ利活用を目的にデータ・エコシステムの標準化や社会実装が進展しつつあり、さらにそのデータ・エコシステムのデータを利活用するニーズがあります。このように多種多様なデータの利活用への対応が課題となっています。
さらに、様々な拠点に遍在するデータの中から目的に合うものを発見できないことや、自身のデータの利用制限や流通状況把握ができない課題も、組織間データ利活用の阻害要因となっています。
技術の概要・特徴・内容
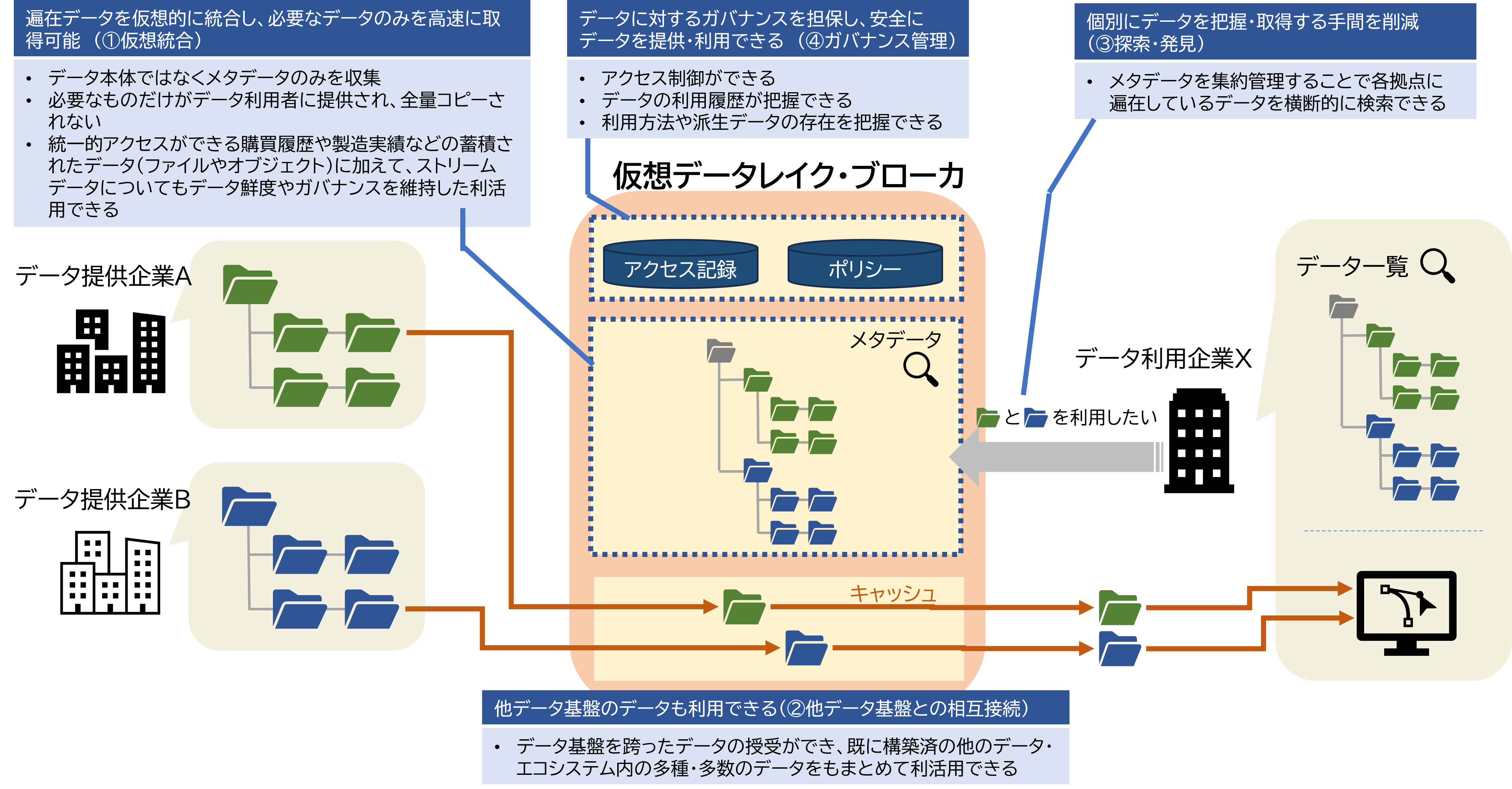
NTTでは、IOWN( Innovative Optical and Wireless Network)の低遅延・大容量性を活用し、効率的かつ安全なデータ利活用を実現するデータハブ基盤の研究開発を進めています。仮想データレイク・ブローカは、データハブ基盤の主要な構成要素であり、多拠点に遍在するデータから利用者が必要なデータの迅速かつ効率的なデータ検索・取得を可能とします。本技術は以下の特徴を有します。
- 【特徴①仮想統合】
-
データ原本を遍在させたまま仮想的に集約するとともに保管場所に依らない高速なデータ取得を実現し、データ利用者に統合的ビューと一元的取り扱いを提供します。遍在するファイルやオブジェクトだけでなくストリームデータについても仮想統合を実現します。
- 【特徴②他データ基盤との相互接続】
-
他のデータ・エコシステムとの相互接続により、他システムで管理するデータの検索・取得を可能にします。
- 【特徴③遍在データの高速な探索・発見】
-
ビジネスメタデータ(例:実データの提供者情報、内容の概略、など)に基づく遍在データの横断的な探索と発見を実現します。
- 【特徴④遍在データのガバナンス管理】
-
流通していくデータに対し管理主体(データ提供者)によるガバナンスの維持(利用制限)を実現します。
以上の特徴により、本技術では複数の組織や拠点のデータをデータ管理主体のガバナンスを維持したまま仮想的に統合し、データ実体は必要時に必要な分だけを高速転送することを可能とします。
技術目標・成果・効果
ここでは前述の特徴についてさらに詳しく説明します(図1)。
【① 仮想統合】
複数の拠点に遍在するデータを活用する場合、従来モデルでは、図2(a)に示すように各拠点のデータを単一の拠点に集約して1つの巨大なデータレイクをつくり、利用者はそこにアクセスすることでデータ利活用を行ってきました。しかし、このモデルでは、データ利用者が実際に利用するデータはごく一部であっても全量コピーが必要となる問題がありました。本技術では、図2(b)に示すとおりデータそのものを収集せずに、各拠点(=データソース)でのファイル作成・更新を検知しテクニカルメタデータとして仮想的に集約・一元化し統合的ビューとして構成します。また、データ取得のための共通インタフェースを提供し、各データソースの違いを意識せず統一的なアクセスを可能にします。
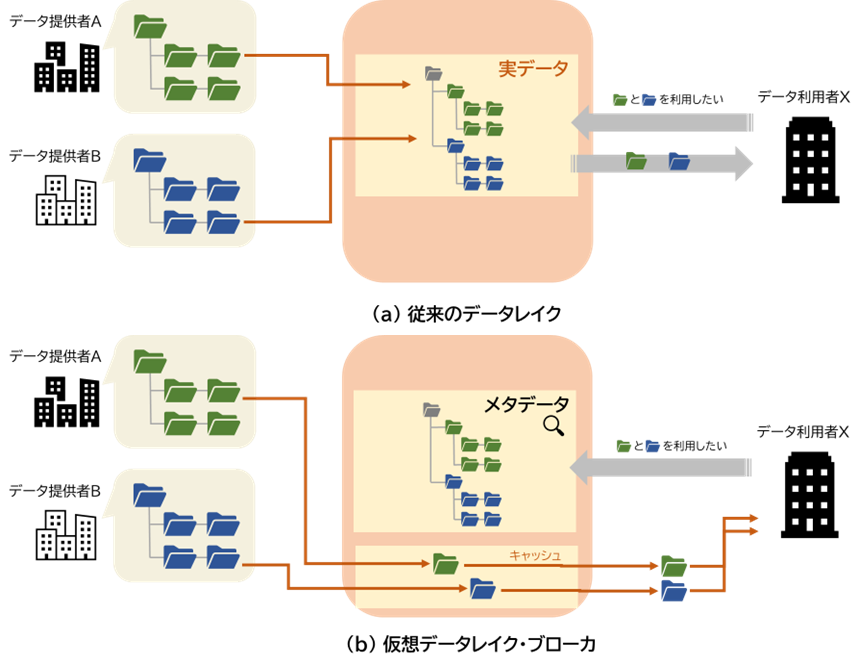
本技術では、購買履歴や製造実績などのオブジェクトストレージ/分散ファイルシステムに蓄積されたデータに加えて、センサ値や制御信号など時々刻々と変化するデータ(ストリームデータ)の仮想統合を実現します。従来、他組織・企業のストリームデータを利活用するには、利用者は多数の提供者が保有する多数のストリームデータから所望のトピックを見つけ出し、提供者ごとに交渉や接続確立する必要がありました。また、関連するトピックのストリームデータを全て受領し、その後、手元で必要な部分の選別・抽出をする必要がありました。これに対し、本技術では、遍在する多数のトピックを仮想的に保持・統合し、所望のストリームデータを利用しやすい形で配信することができます。また、属性ベースのアクセス制御ポリシーに基づく高度な認可制御を高速に処理する技術により、ストリームデータについてもデータ提供者のガバナンスとデータの鮮度を両立することができます。
【② 他データ基盤との相互接続】
従来、異なる仕様で構築されたデータ基盤間でのデータの連携は、データ基盤の仕様間の思想やモデルの差異により困難でした。結果としてデータ基盤毎のサイロ化が起き、それぞれの範囲内でのデータ利活用に留まっていました。本技術では、他データ基盤仕様との間の思想やモデルの差異を吸収し、他データ基盤内のデータへの一元的で容易なアクセスを実現する技術により、統合対象を他データ基盤内で管理されるデータに拡大することができます。これにより、データ基盤を跨ったデータの授受を可能とし、既に構築済の他のデータ・エコシステム内の多種・多数のデータをもまとめて利活用するサービスの容易かつ迅速な提供を可能とします。
【③ 遍在データ探索・発見】
データ利用者は、様々なデータ提供者が保持する形式や品質の異なる膨大なデータから目的達成に必要なデータを効率的に発見し活用する必要があります。これに対して、本技術はビジネスメタデータを含む統合的なビューを構成し、閲覧可能にして横断的な検索を可能にします。
また、リネージュデータと呼ばれるデータの出自から流通経路や加工プロセスに至る情報もメタデータとして付与し管理することができます。データ間の関連性をたどることより、データ利用者が曖昧な手掛かりしかない場合でも必要なデータを発見しやすくなります。また、データに不適切な加工がなされていないことや出自が不明な怪しいデータではないことを確認でき、データの信頼性を判断できるようになります。
【④ 遍在データガバナンス管理】
データ提供者の視点からは自身のデータが大量に生成されるとデータへのガバナンス(利用制限)が効かなくなるという問題がありました。本技術では、データ提供者は原本となるデータを常に自拠点で管理し、予め許可した要求に応じて本技術を介してデータを提供することで、自身のデータに対するガバナンスを維持することが容易となります。データの公開可否に加えて、派生データに対してもポリシーを記述でき、遵守させることができるため、データ提供者のデータ主権、すなわち「データ所有者が自分のデータを利用制限および管理する権利」を担保することができます。
想定される適用分野・PoC
〇道路交通の整流化
渋滞予測、信号制御など交通流を最適化する道路交通の整流化では、異なるデータ提供者から複数のセンサデータや映像データといったリアルタイムデータの分析・解析が必要となります。解析に必要なデータを企業横断で検索し、必要なデータを必要なときだけ取得するために本技術が役立つと考えられます。
〇電力需給最適化
近年、個人による自家発電も増えており、発電量に余裕がある需要家は電力が不足しそうな需要家へ電力融通する需要家間融通が考えられています。需要家の発電量と電力需要に関するデータをリアルタイムに取得・提供して取引を成立させるために、本技術が役立つと考えられます。
〇サプライチェーンGHG排出量の算出
自動車等の製品は多数の国内、海外の部品メーカーの部品から構成されており、各部品メーカーからGHG排出量データ(Green House Gas:二酸化炭素やメタンなど温室効果ガスの排出量)や部品の製造に関連するデータなどを取得するケースが出てきています。必要なデータはサプライチェーン全体で多岐にわたり、遍在しています。複数企業の多種・多数のデータを集約している他エコシステムのデータをまとめて利活用するには、本技術の相互接続機能が役立つと考えられます。
今後の展望
仮想データレイク・ブローカの研究開発をIOWN技術のAPN(All-Photonics Network:オールフォトニクス・ネットワーク)や DCI(Data-Centric Infrastructure subsystem:データセントリック基盤)を活用した技術・プロダクトの開発へシフトしていく予定です。具体的には、DPU(Data Processing Unit)などのハードウェア・アクセラレータを活用した処理効率化・高速化を行うことで、組織や企業の垣根を越えた安心・安全で便利なデータ利活用を更に高速に実現可能とし、新たな価値の創出や社会課題の解決に役立たせたいと考えています。