イベントドリブン型推論基盤技術
大量なカメラ映像分析における膨大なコストを削減する推論処理高効率化技術

技術背景・課題
IOWN構想を実現する1つのアプローチとして、実世界を仮想空間に再現し、さらに事象の解析や予測を行うことにより新たな価値をもたらすことが期待されています。ここで、実世界を仮想空間に再現するためには、状況認識のために大量のカメラ映像の分析が必須となります。このような大量のカメラ映像の分析には、膨大な計算機リソース、膨大な消費電力が必要です。NTT研究所では、これらの膨大なコストを削減する技術の研究開発を進めています。
技術の概要・特徴・内容
従来技術では、全てのカメラ映像に対して推論処理を実施し、膨大なコストを必要としていました。「イベントドリブン型推論基盤技術」は、分析目的の実現に対して不要と考えられる推論処理を減少させることで、映像分析に必要な推論処理量を削減します。これにより、映像分析に必要なGPUなどの推論計算機リソース(設備量)、推論処理に必要な消費電力量を削減する効果が得られます。本技術で採用する推論処理量の削減方式は、大きく下記の2つに分類でき、またこれらを組み合わせて活用することも可能です。
- 単一のカメラ映像を分析する際の推論処理量削減:イベントを検知した時のみ推論処理を実施することで、従来技術よりも推論処理を削減
- 複数のカメラ映像を連携させて事象を観測する際の推論処理量削減:あるカメラ映像でイベントを検知した時のみ他のカメラ映像を分析することで、従来技術よりも推論処理を削減
技術目標・成果・効果
映像は、時系列の複数の画像から構成されています。「イベントドリブン型推論基盤技術」におけるイベント発生とは、カメラ映像のうち、分析目的の実現のために「詳細な推論処理」が必要な画像を特定するための条件を満たした状況を指します。例えば、固定カメラで歩行者を検知したい場合において、イベント発生とは、「時系列上で前後の画像に差分がある状況」と事前に定義します。この定義を適用したイベントドリブン型推論基盤上で推論処理を実行した場合、歩行者が一人も映っていない画像に対して詳細な推論処理は行われないため、詳細な推論処理の実行回数(頻度)を削減することができます。「イベントドリブン型推論基盤技術」とは、このようなイベント発生時のみ、詳細な推論処理を実施することで、映像分析に必要な推論処理量を削減します。
下記に、「イベントドリブン型推論基盤技術」の取り組みと効果について、「1. 単一のカメラ映像を分析する際の推論処理量削減」と「2. 複数のカメラ映像を連携させて事象を観測する際の推論処理量削減」に分けてご紹介します。
1. 単一のカメラ映像を分析する際の推論処理量削減
スマートシティにおける大量の固定の監視カメラ映像を分析する際の推論処理量削減を目指し、イベント発生時のみ推論処理を実行すること(時間的な特性に着目したイベントドリブン型推論方式)、その分析対象の動きに応じて推論処理頻度を落としたり、その映り方に応じて総推論処理量が小さくなるように推論モデルを使い分けたりすること(空間的な特性に着目したイベントドリブン型推論方式)により、カメラ映像の推論処理量を削減することができます。
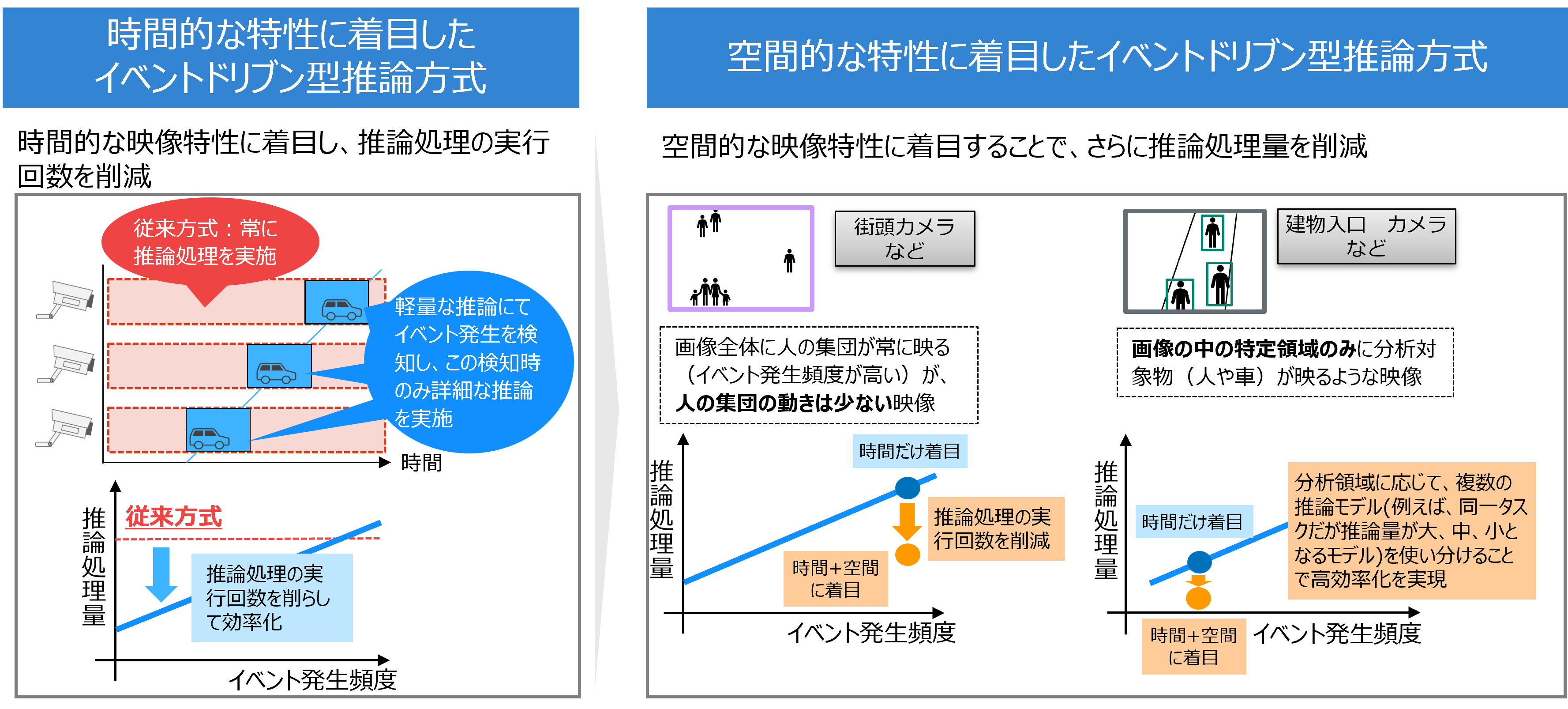
上記技術を活用するためには、遮蔽のない高い位置に設置され、背景は固定であり、イベントが比較的大きく映るといった、イベント発生が容易に検知可能であるという条件を満たす必要があります。一方で、車載カメラなどの移動カメラを対象とした場合、この条件を満たすことが難しいです。その場合には、本来サービスに利用する詳細な推論モデルを利用してイベント発生を検知することが可能です。また、イベントは連続して発生しやすいという傾向に着目し、一定間隔でフレーム画像を間引きつつ詳細な推論モデルで分析することでイベントの発生を検知し、イベント発生検知時にイベント前後のフレーム画像を推論対象として動的に選択すること(イベントドリブン型 動的フレーム間引き推論方式) で推論処理頻度を削減することができます。
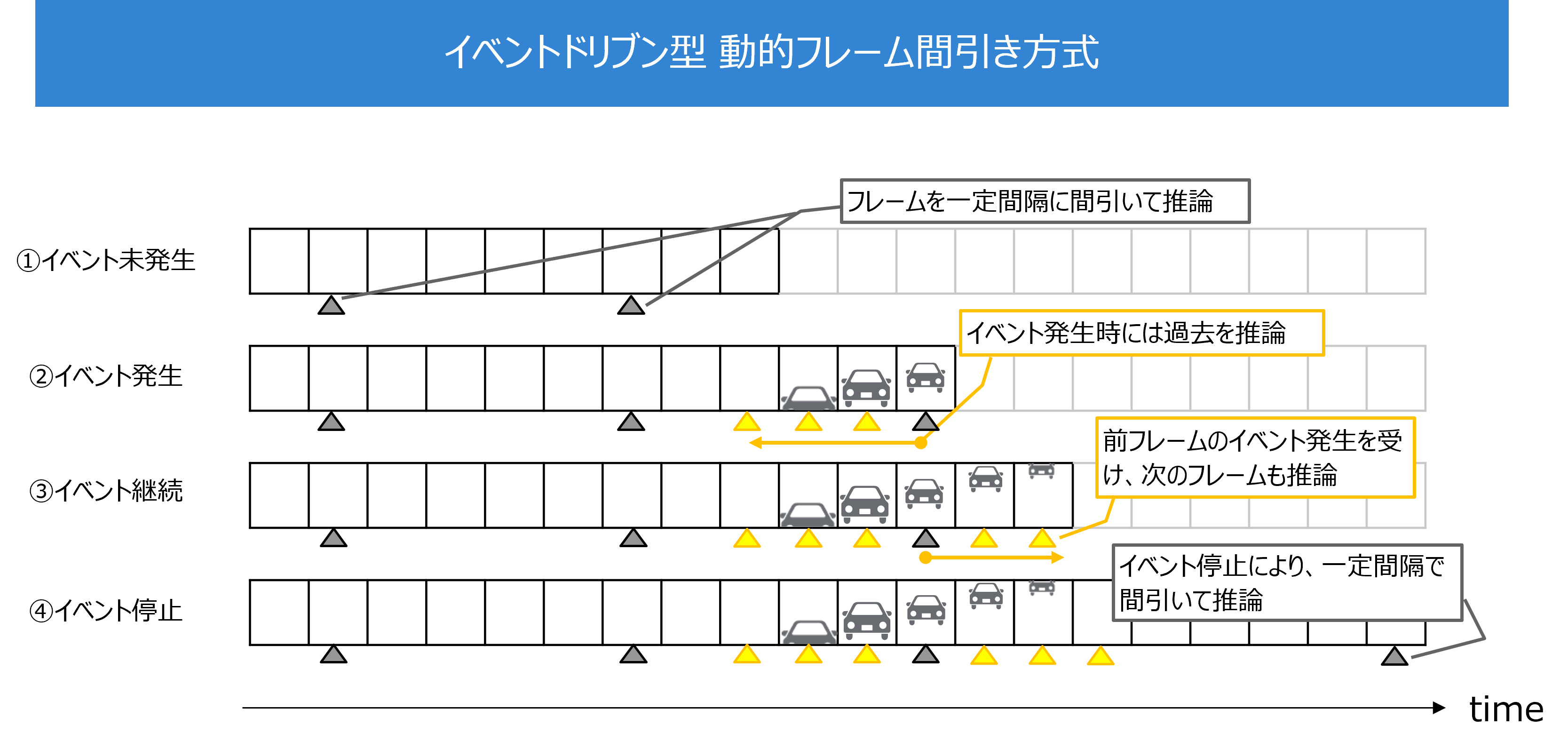
2. 複数のカメラ映像を連携させて事象を観測する際の推論処理量削減
モビリティを含めたスマートシティにおいて、自転車や歩行者といった分析対象が移動する場合、これらを検知し継続的に監視するためには、複数のカメラ映像を分析する必要があります。この場合、従来技術では不要なカメラの映像分析まで実行される問題がありました。この問題を解消するため、状況に応じて映像分析すべきカメラを動的に選択、また、複数のカメラ映像の推論結果を共有することで、分析対象とするカメラ選択の判断にフィードバックを行います。これにより、不要なカメラ映像に関する推論処理を減らし、システム全体の推論処理量削減を実現します。
これを「イベントドリブン型 多段推論方式」と呼び、不要なカメラ映像に関する推論処理を減らし、システム全体の推論処理量削減を実現します。
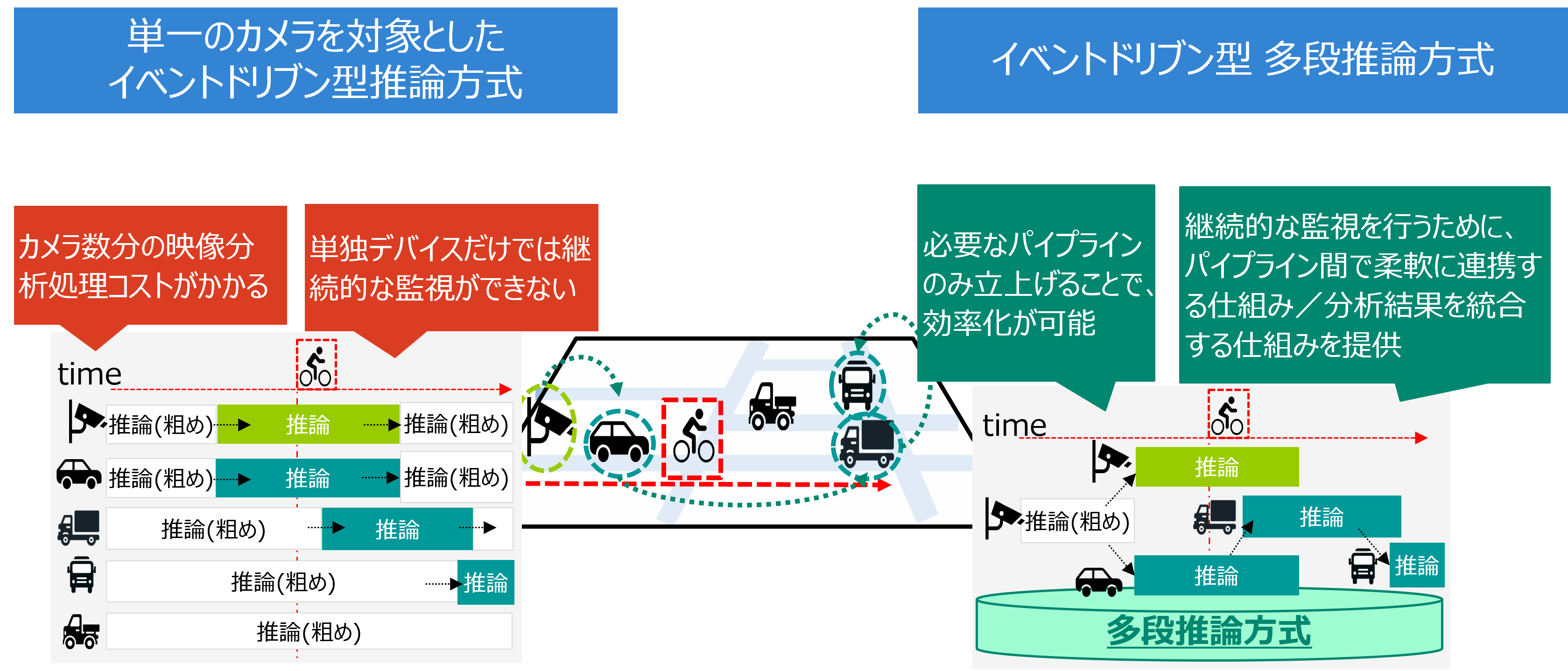
これらの技術に加え、複数箇所で求められる推論処理を一箇所のGPUリソースに集約するGPUリソースプールに関する独自技術を適用し、さらにKubernetesなどのコンテナベースのオーケストレーション技術も活用することで、推論基盤の開発を進めています。加えて、検証を実施し、従来技術と比較して、映像分析に必要なコスト(計算リソース量・消費電力量)をイベント発生率程度に抑える効果が得られることを確認しています。
想定される適用分野・PoC
下記のようなユースケースに適用することで映像分析に必要なコストを削減することが可能です。
■防犯カメラといった単一の固定カメラ映像を活用した映像分析サービス
- 例えば、店舗での万引き防止、建設現場での危険検知、工場や工事現場での業務中の行動分析 など
■モビリティを含めたスマートシティ市場における複数のカメラ映像を活用した映像分析サービス
- 例1:都道府県といった広域を対象とし、複数の移動カメラからの映像を活用することで、工事や店舗入り口のレーン別渋滞などを検知し、継続的に監視することにより状況に応じて最適なナビゲーションを提供するサービス
- 例2:固定カメラが設置されていない交差点などを対象とし、他車の移動カメラ映像を活用することで、死角となる道路状況を継続的に監視した上で飛び出し可能性などを判断し、周辺の車に通知するサービス
今後の展望
今後は、映像のみではなく言語といった異なるモーダルデータも対象とすることで、活用可能なユースケースを拡張し活用範囲の拡大を目指します。また、単一のデータセンタのみではなく、モバイルエッジコンピューティングも含めたエッジとデータセンタといった分散されたコンピューティング環境上で実行されるAI推論基盤のリソース最適化を目指すとともに、IOWN 光ディスアグリゲーテッドコンピュータ技術と組み合わせて利用可能とすることで、電力効率に優れたデータセンタの実現に貢献していきます。