
10/20/2025
NTT's Large Language Models 'tsuzumi 2'NTT Human Informatics Laboratories
NTT's Large Language Models 'tsuzumi 2'
NTT has released a new version of its large language model, tsuzumi 2, which offers an excellent balance between operational efficiency and performance. This lightweight model can run on just one GPU while delivering top-tier performance comparable to ultra-large-scale language models.
NTT Human Informatics Laboratories
Top-Tier Performance Approaching Ultra-Large-Scale Models
tsuzumi 2 achieves high scores across many benchmarks, including MT-bench. The figure below shows a comparison between tsuzumi 2 and GPT-5 on the MT-bench (Turn1 in Japanese). MT-bench evaluates language models through diverse tasks, providing insights into their capabilities from various perspectives. tsuzumi 2 performs nearly as well as GPT-5 across most tasks, demonstrating its ability to handle complex user requests effectively.
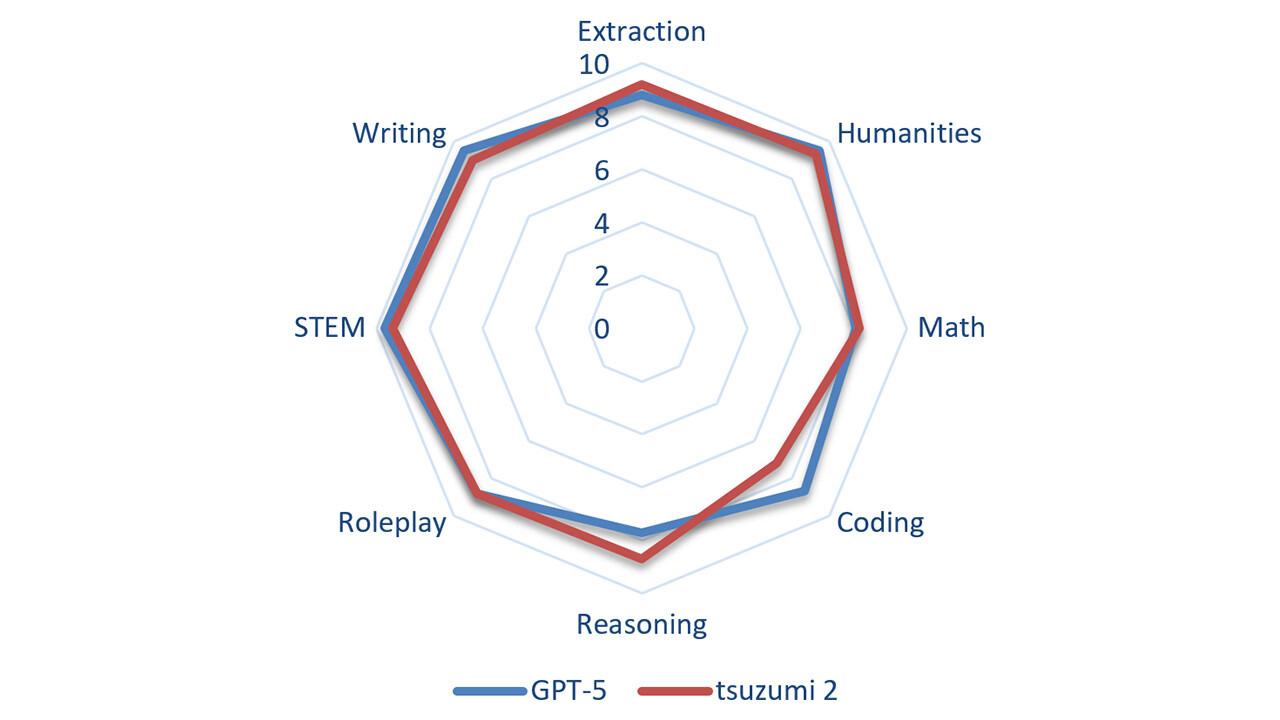
Figure 1. Comparison of Tsuzumi 2 and GPT-5 on MT-Bench (Japanese)
Lightweight Model Operable on 1 GPU
tsuzumi 2 is designed to run efficiently on a single GPU. While many modern language models require high-spec, expensive GPUs with over 40 GB of memory, tsuzumi 2 targets older or more modestly equipped devices. As the use of large-scale language models expands across various industries, the cost associated with frequent API usage can become prohibitive for some customers. Additionally, as AI agents and system integrations increasingly rely on sensitive data, there is a growing demand for on-premises deployment solutions like tsuzumi 2.
Enhanced Task Processing Capabilities for Corporate Users
tsuzumi 2 focuses on strengthening tasks that are most frequently used in business scenarios:
- QA (Question Answering) on Documents (RAG search and summarization)
- Information Extraction and Summarization from Documents
For these use cases, we developed a proprietary evaluation set tailored to practical business applications. Compared to its predecessor, tsuzumi 2 shows significant improvements in performance on these tasks.
In addition, tsuzumi 2 has been extensively trained with extensive knowledge specific to sectors where NTT has many clients:
- Finance
- Municipal Governments
- Healthcare
These domain-specific enhancements enable tsuzumi 2 to deliver superior results in various use cases within these fields.

Figure 2. Typical Usage Patterns of Large Language Models at NTT's Corporate Customers

Figure 3. Comparison Between tsuzumi 2 and Its Predecessor on Key Tasks
Corporate customers often require precise output formats, such as:
- Summarization adhering to specific reporting styles
- Extraction of certain information formatted in JSON
To meet these needs, tsuzumi 2 has been enhanced for instruction following, ensuring it is a highly usable model.
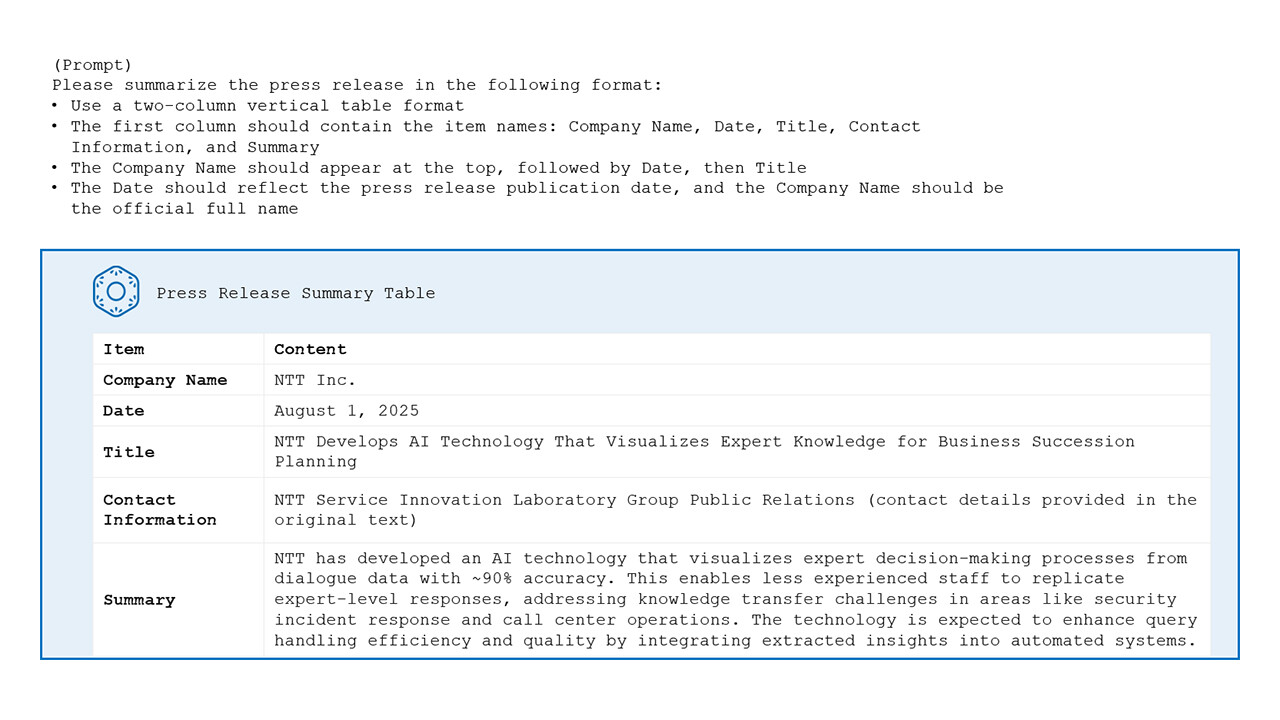
Figure 4. tsuzumi 2 Example: Summary of an Announcement. Press Release Summary of "NTT Develops AI Technology That Visualizes Expert Knowledge for Business Succession Planning - Leveraging LLM to model expert decision-making processes using dialogue data- | Press Release | NTT"

Figure 5. tsuzumi 2 Example: Extracting Information in a Specified Format from the Source Code of "Group Companies | About NTT | NTT"
Japan Domestic Model Developed Entirely by NTT
Recent lawsuits regarding unauthorized use of newspaper data in language model training have raised concerns about development practices. Using models tainted by such issues could expose users to liability risks. To address this, NTT has chosen full-scratch development, building the model entirely from scratch without relying on pre-existing open-source models as a foundation. This approach allows complete control over learning datasets, ensuring compliance with rights, quality standards, and minimizing biases--critical factors for enhancing model reliability. Like its predecessor, tsuzumi 2 is developed in accordance with domestic Japanese laws and regulations, making it a purely domestically produced model.
Associated Resources
- August 6, 2025 - Financial Results Presentation Materials [PDF: 1.8MB]
https://group.ntt/en/ir/library/presentation/2025/250806e.pdf - About NTT's AI | NTT Group Initiatives
https://group.ntt/jp/group/ai/