Machine Translation
Toward Machine Translation considering Context and Situation
The use of neural networks has improved the accuracy of machine translation greatly. Although we have achieved practical accuracy in translating daily conversations and short sentences, it is far from understanding the context and situation to appropriately translate a document or meeting, which consists of multiple sentences or a series of interactions. NTT is working on creating a Japanese-to-English discourse translation test set, building a large-scale Japanese-English bilingual corpus, and researching highly accurate sentence and word alignment algorithms to achieve highly accurate machine translation that takes context and situation into account.
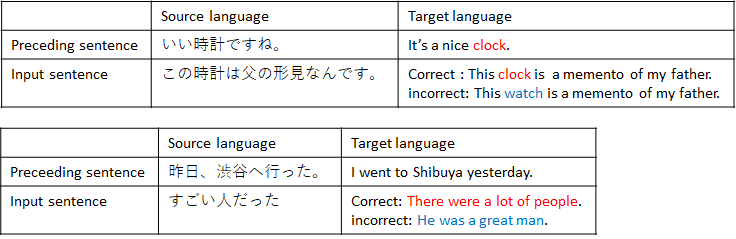
Japanese-to-English Discourse Translation Test Set
One of the problems with previous automatic evaluation metrics is that it cannot measure whether a machine translation system understand the context or not. NTT has created a Japanese-to-English discourse translation test set that focuses on co-reference and consistency and make it open to the public.
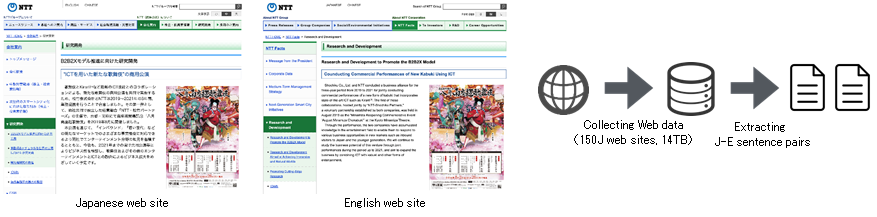
Large-scale Japanese-English Bilingual Corpus: JParaCrawl
We have created JParaCrawl, a data set of more than 10 million Japanese and English sentence pairs. It is made by extensively crawling the Web and extracting sentence pairs that are translations of each other. By combining JParaCrawl with small-scale bilingual data for a specific field, such as medicine and finance, we can easily create a machine translation system for it. NTT has made JParaCrwal available free of charge for research purposes only. JParaCrawl is used in the Japanese-to-English and English-to-Japanese news translation shared tasks at the Conference on Machine Translation (WMT), a leading international conference on machine translation.
Word and Sentence Alignment based on Cross-Language Span Prediction
Identifying sentences that are translations of each other in bilingual documents (texts) is called sentence alignment. Identifying words that are translations of each other in bilingual sentences is called word alignment. NTT has devised a new method called cross-language span prediction based on question answering technology to address these tasks and achieved highly accurate word and sentence alignment. This technology makes it easy to extract bilingual sentence pairs from bilingual texts. It also makes it easy to map word attributes such as boldface and hyperlink from a source sentence to the target one. We have released the software for verification.
- A Word Alignment software using multilingual BERT
- SpanAlign: Sentence Alignment Method based on Cross-Language Span Prediction and ILP
